论文链接:
http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
背景:
LeNet,也被称为LeNet-5,是卷积神经网络(CNN)的开山之作
LeNet-5网络结构
发展历史:
- 1989年: Yann LeCun等人,结合反向传播算法的卷积神经网络来识别手写数字,并成功地用于识别手写邮政编码。
- 1990年:他们的模型在美国邮政总局提供的邮政编码数字数据的测试结果表明,错误率仅为1%,拒绝率约为9%。
- 1998年:他们将手写数字识别的各种方法在标准的手写数字识别基准上进行比较,结果表明他们的网络优于所有其他模型,经过多年的研究和迭代,最终发展成为LeNet-5。
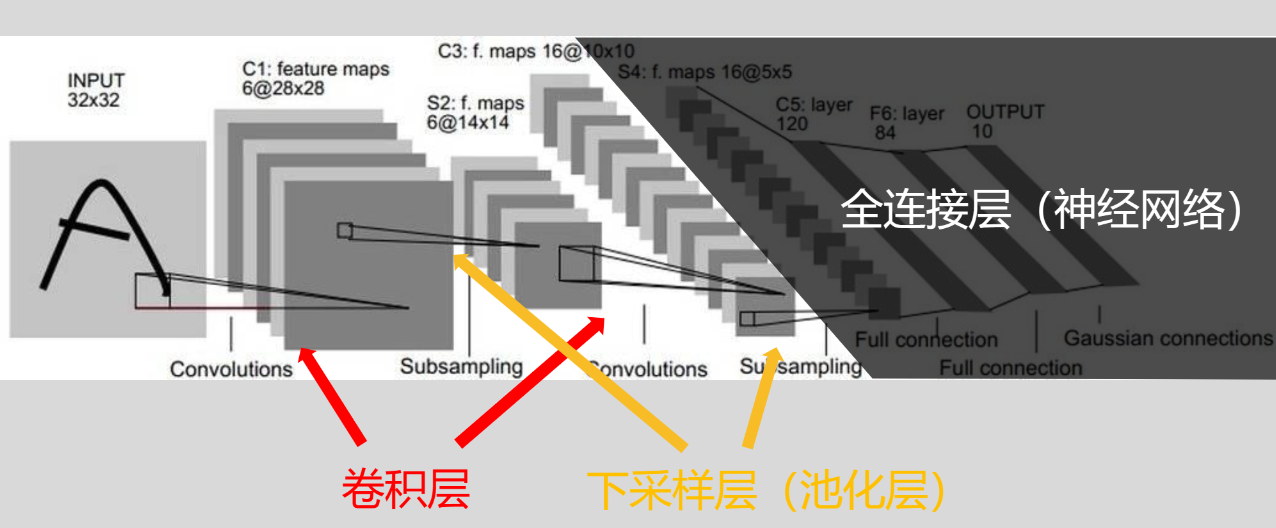
卷积层:卷积过程指计算机找到的一些特征(成为卷积核)依次作用于原始像素,对应位置相乘再相加,最后再除以卷积核的数量,得到输出结果。
池化层:池化是指将输入每一个位置的矩阵,[n*n]选取这个矩阵种数据的最大值(最大池化)或者平均值(平均池化)
通过卷积、ReLU激活、卷积、ReLU激活、池化、卷积、ReLU激活、池化最终等到了参数较少,但是依旧能保持原始特征信息的特征图。
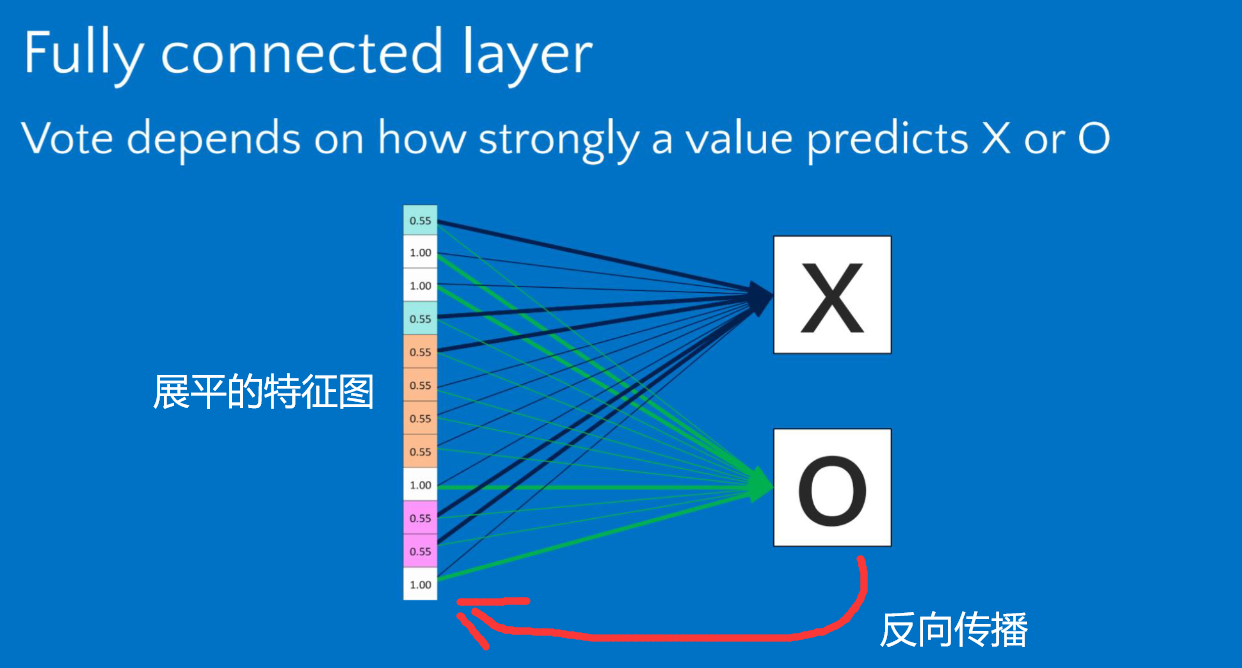
将特征图展平,进入神经网络,得到预测的概率(n分类问题、每一个类都对应得到一个概率)通过反向传播的方式,不断调整参数。以达到预测值和真实值最接近的情况,完成网络的训练。
LeNet-5搭建与训练
具体结构:
第一层是卷积层,对原始图像,做5*5的卷积操作,有6个卷积核,得到了6个卷积后的特征图。
第二层是池化层,每次扫过特征图的四个区域,提取其最大值或者平均值进行池化,使得整体网络的参数变小,同时保留特征。
第三层是卷积层,拥有16个卷积核,每一个卷积核有6个部分 ,可以同时对6个池化后的特征图做卷积操作。最终生成16个特征图。
第四层是池化层,对16个特征图进行池化,使参数进一步减少。
第五层是展平层(仍是卷积操作),将这16个特征图通过120个与原图相同尺寸卷积核的卷积,展平成120个1*1大小的向量。
第六层是由84个神经元组成的全连接层,与展平的120个向量进行全连接操作,生成84个神经元数据。
最后由于是一个十分类问题,在输出层设置10个神经元,分别输出十个概率,预测手写的数字,最大概率是哪一个。
模型的相关参数:
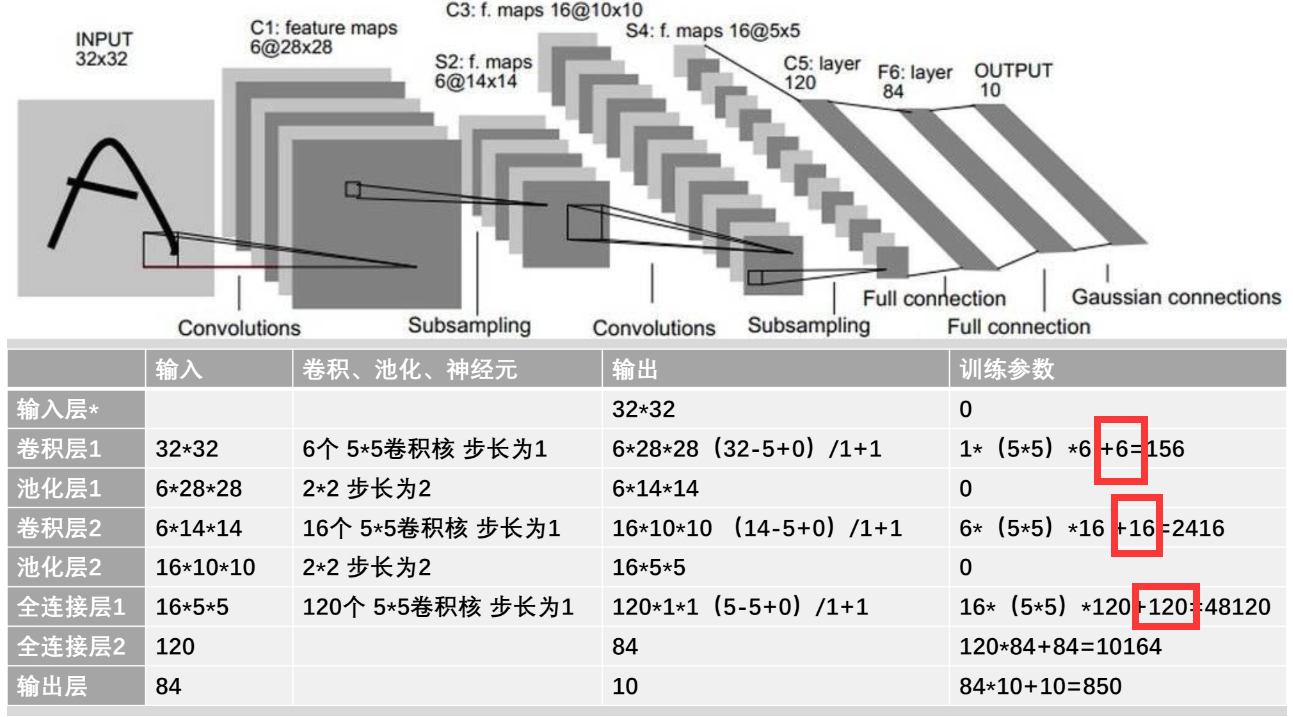
训练的参数,不仅包括卷积核,而且包含一个与卷积核个数相同的偏置,偏置的解释如下图
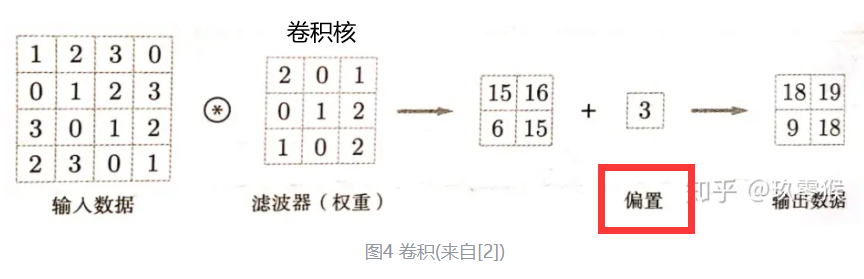
特别注意这里的卷积层2,是用16个卷积核,每个卷积核由6个部分(每个部分是5*5)分别对输入的6个特征图做卷积生成一块数据。(6合1)
LeNet-5保存、调用和预测
该块分为四步:
数据采集:数据集的预处理,增加维度以满足卷积操作,数据集归一化、标签进行独热编码。
建立模型:使用keras.Sequential的顺序结构搭建模型。包括上述提到的各个层,且可以对网络进行预览。
模型训练:找到使得损失函数最小值的权重和偏置项。
模型测试:网络保存及调用加载已经训练的模型结构和权重,读取我们要测试的图片,经过预处理之后作为输入加载到模型之中。得到预测结果并打印。
模型的训练
模型源码:
注意安装这几个库的版本,可能因为版本问题无法加载数据集,建议自己选择合适的版本。
1 | import tensorflow as tf |
归一化:通过归一化,可以确保不同特征或变量的值在相同的范围内,避免了某些特征对模型训练的主导作用,同时提高了模型的收敛速度和稳定性。此外,归一化还可以防止异常值对模型的不良影响,使得模型更具鲁棒性。
代码调试模型训练:

加载数据集成功。
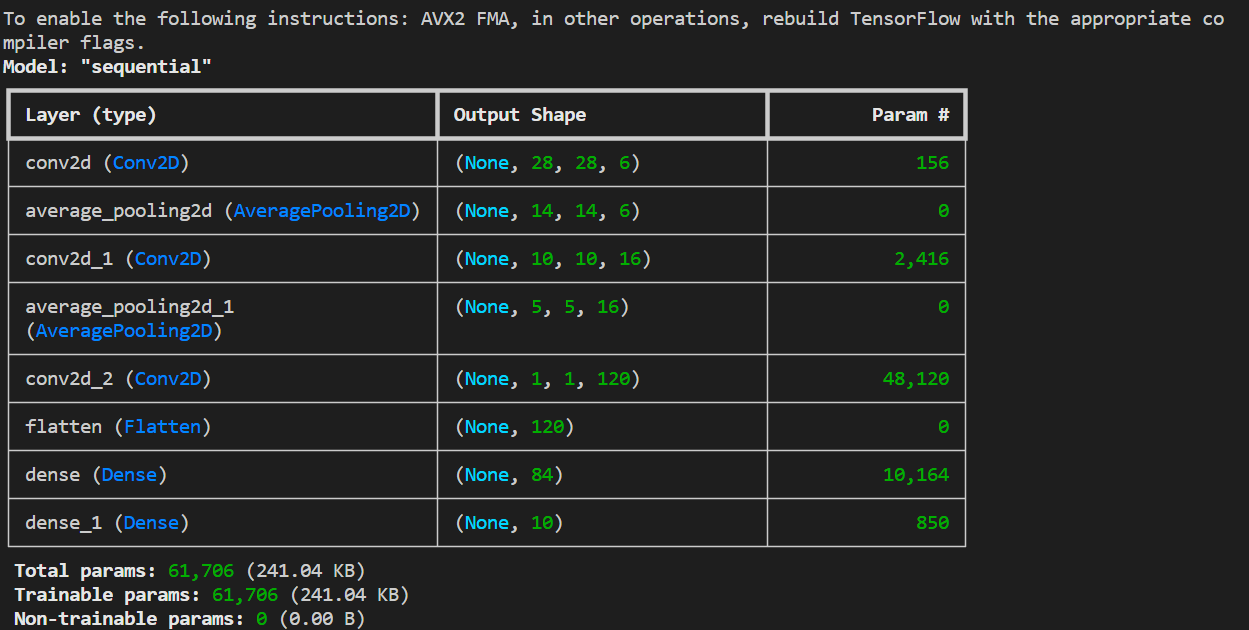
整个网络的结构。包括一些训练参数的个数以及总的参数的个数。
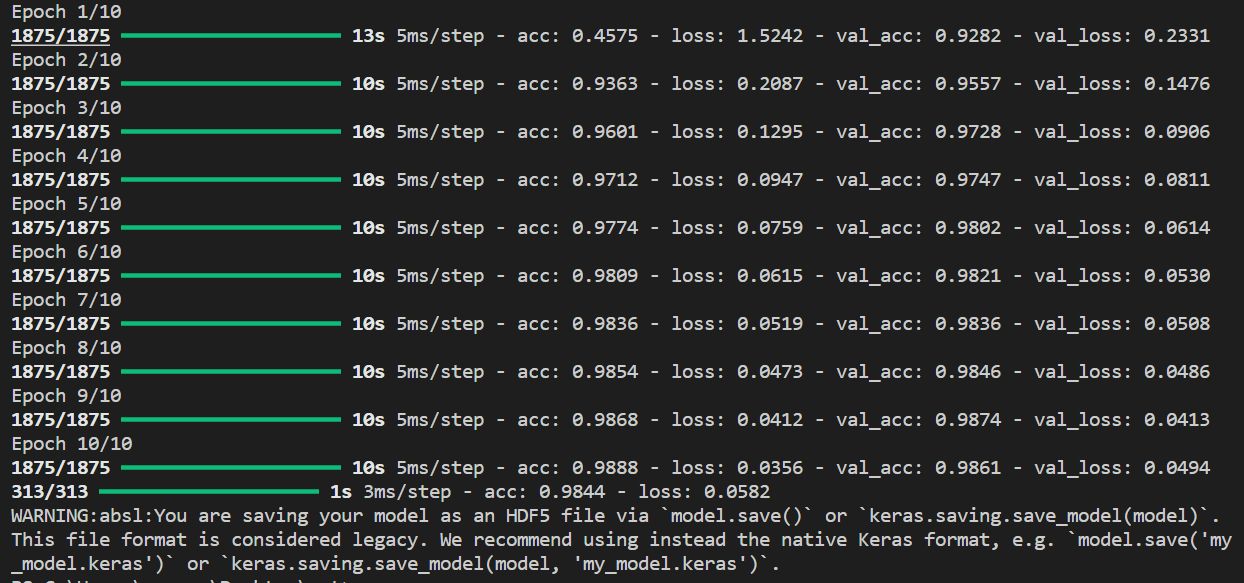
把训练图片训练标签作为输入,测试图片测试标签作为每轮的验证,进行十轮的训练。经过十轮的训练,在验证集和训练集上的准确率达到了98%左右
然后进行模型的评估,acc:0.9844;loss:0.0582
最后将训练好的模型进行保存,以方便后续进行预测和评估。
画图
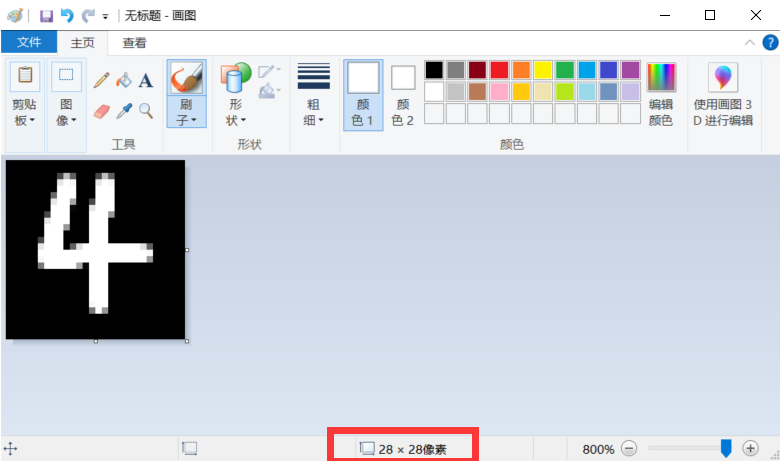
使用画图工具,设置像素比例为28*28。
将背景填充为黑色,使用白色刷子绘制图片
将图片命名为4.png,保存在LeNet5.py、mnist.h5相同目录下
模型的调用
调用函数代码(4.png)
1 | import tensorflow as tf |
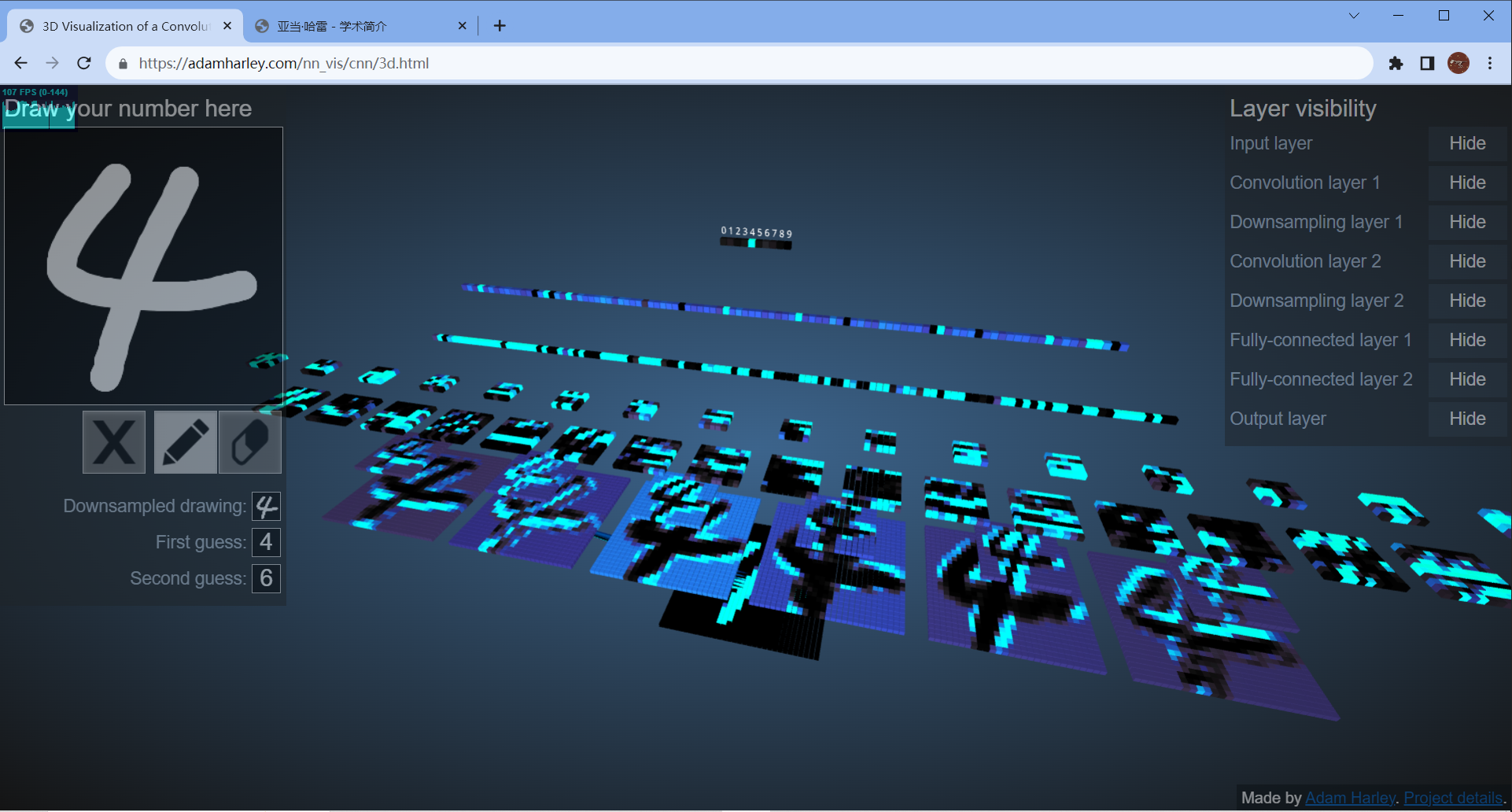
预测过程:
如下图所示,加载了一张图片进行预测(4.png)
predict记录了该图片在0-9上预测值的概率分布
选择概率最大的作为第一预测输出,概率第二大的作为第二预测输出。




